CUDA is a system that allows us to write programs on the GPU. CUDA programs are basically C or C++ programs, with the extension of extra keywords that allow us to specify parallelism.
Parts of a CUDA program execute on the CPU, while other parts execute on the GPU. CUDA allows us to specify which parts execute on the GPU as well as manage GPU memory.
CUDA was created by NVIDIA and is only supported on NVIDIA GPUs. OpenCL provides a way to write parallel code for multiple types of GPUs, but is more complex than CUDA.
Graphics processing units were originally created for rendering graphics quickly. This involves a few common operations:
These operations also must be applied to large numbers of vertices or pixels, opening up the possibility of data parallelism.
These capabilities are great for many other computational tasks.
GPUs are much different than CPUs:
CUDA programs are composed of two different parts:
An important part of CUDA programming is managing memory. CPU and GPU memory is distinct. The GPU is completely separate from the CPU and is not a part of the cache hierarchy.
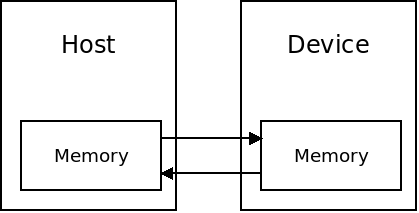
For this reason, we must explicitly pass data between the CPU and GPU when writing CUDA programs.
GPU memory is completely separate from CPU memory. In order to allocate memory on the GPU, we call the cudaMalloc function:
cudaError_t cudaMalloc(void** pointer, int bytes)This function takes the address of a pointer, and the number of bytes to allocate. It creates the memory on the GPU and returns a handle to it in the pointer which is passed in.
This pointer cannot be directly accessed as it doesn't point to a memory address on the CPU. To store anything on the GPU, we must use the cudaMemcpy function:
cudaError_t cudaMemcpy(void* destination, void* source, int bytes, cudaMemcpyKind kind)This function copies the specified number of bytes from the source location to the destination. "kind" can be one of:
There is not much reason to use "host to host", as the regular memcpy function can be used. For transferring memory to or from the device, however, these functions are necessary.
The CUDA programming model involves passing data to the GPU in "blocks" which are arrays of some dimension. CUDA automatically divides these blocks up amongst multiple GPU cores.
The blockIdx variable is available which contains the indices this core is supposed to be processing. If we are processing a 1D array, then blockIdx.x gives us the index. For 2D or 3D arrays, blockIdx.y and blockIdx.z give the second and third dimension.
The following is a hello world program in CUDA:
#include <stdio.h>
#define N 16
#define CORES 16
/* this is the GPU kernel function */
__global__ void hello(char* s) {
/* blockIdx is a struct containing our block id
if this this is a one-dimensional kernel, then x is the block id
y and z are also available for 2 or 3 dimensional kernels */
/* capitalize the string by subtracting 32 from each lowercase letter */
if ((s[blockIdx.x] >= 'a') && (s[blockIdx.x] <= 'z')) {
s[blockIdx.x] -= 32;
}
}
/* the main function begins running on the CPU */
int main() {
/* this is the string data - it is 'hello world', in lower-case */
char cpu_string[N] = "hello world!";
/* allocate space on the GPU for the string */
char* gpu_string;
cudaMalloc((void**) &gpu_string, N * sizeof(char));
/* send the character array to the GPU */
cudaMemcpy(gpu_string, cpu_string, N * sizeof(char), cudaMemcpyHostToDevice);
/* invoke the GPU to run the kernel in parallel
we specify CORES cores which each run once */
hello<<<CORES, 1>>>(gpu_string);
/* copy the string back from the GPU to the CPU */
cudaMemcpy(cpu_string, gpu_string, N * sizeof(char), cudaMemcpyDeviceToHost);
/* free the memory we allocated on the GPU */
cudaFree(gpu_string);
/* print the string we got back from the GPU */
printf("%s\n", cpu_string);
return 0;
}
GPUs typically do not do input or output, but only computation. So this hello world program has the GPU "compute" the string "HELLO WORLD" by capitalizing the string stored on the CPU.
Note that there is no loop in the program. Invoking the hello function on 16 cores will automatically launch 16 instances of the function on 16 GPU cores. Each will have a different blockIdx.x so each spot in the array will be processed.
CUDA is not installed on the cpsc server because it does not have CUDA capable graphics cards.
On a machine that does have the CUDA compiler, we can compile and run our hello world program:
$ nvcc hello.cu $ ./a.out
CUDA can be used with C++ as easily as it can be used with C.
/* hello.cu */
#include <iostream>
using namespace std;
const int N = 16;
const int CORES = 16;
/* this is the GPU kernel function */
__global__ void hello(char* s) {
/* blockIdx is a struct containing our block id
if this this is a one-dimensional kernel, then x is the block id
y and z are also available for 2 or 3 dimensional kernels */
/* capitalize the string by subtracting 32 from each lowercase letter */
if ((s[blockIdx.x] >= 'a') && (s[blockIdx.x] <= 'z')) {
s[blockIdx.x] -= 32;
}
}
/* the main function begins running on the CPU */
int main() {
/* this is the string data - it is 'hello world', in lower-case */
char cpu_string[N] = "hello world!";
/* allocate space on the GPU for the string */
char* gpu_string;
cudaMalloc((void**) &gpu_string, N * sizeof(char));
/* send the character array to the GPU */
cudaMemcpy(gpu_string, cpu_string, N * sizeof(char), cudaMemcpyHostToDevice);
/* invoke the GPU to run the kernel in parallel
we specify CORES cores which each run once */
hello<<<CORES, 1>>>(gpu_string);
/* copy the string back from the GPU to the CPU */
cudaMemcpy(cpu_string, gpu_string, N * sizeof(char), cudaMemcpyDeviceToHost);
/* free the memory we allocated on the GPU */
cudaFree(gpu_string);
/* print the string we got back from the GPU */
cout << cpu_string << endl;
return 0;
}
We can compile and run C++/CUDA code exactly the same as C/CUDA code.
The nvcc program passes all __global__ functions to a special compiler for CUDA, and compiles the rest of the code with a C++ compiler. Because C is nearly a subset of C++, we can use C or C++.
The "regular" functions in a CUDA program can be any arbitrary C or C++ code.
The __global__ functions, are CUDA code, however. There are some limitations in what can be used in these. The following program is identical to the Hello World program above, except that it uses the C functions isupper and toupper:
#include <unistd.h>
#include <ctype.h>
#include <stdio.h>
#define N 16
#define CORES 16
/* this is the GPU kernel function */
__global__ void hello(char* s) {
/* blockIdx is a struct containing our block id
if this this is a one-dimensional kernel, then x is the block id
y and z are also available for 2 or 3 dimensional kernels */
/* capitalize the string by subtracting 32 from each lowercase letter */
if (isupper(s[blockIdx.x])) {
s[blockIdx.x] = toupper(s[blockIdx.x]);
}
}
/* the main function begins running on the CPU */
int main() {
/* this is the string data - it is 'hello world', in lower-case */
char cpu_string[N] = "hello world!";
/* allocate space on the GPU for the string */
char* gpu_string;
cudaMalloc((void**) &gpu_string, N * sizeof(char));
/* send the character array to the GPU */
cudaMemcpy(gpu_string, cpu_string, N * sizeof(char), cudaMemcpyHostToDevice);
/* invoke the GPU to run the kernel in parallel
we specify CORES cores which each run once */
hello<<<CORES, 1>>>(gpu_string);
/* copy the string back from the GPU to the CPU */
cudaMemcpy(cpu_string, gpu_string, N * sizeof(char), cudaMemcpyDeviceToHost);
/* free the memory we allocated on the GPU */
cudaFree(gpu_string);
/* print the string we got back from the GPU */
printf("%s\n", cpu_string);
return 0;
}
This code does not compile however:
hello-fail.cu(17): error: calling a __host__ function("isupper") from a __global__ function("hello") is not allowed
hello-fail.cu(18): error: calling a __host__ function("toupper") from a __global__ function("hello") is not allowed
The CUDA code in a __global__ function cannot call functions on the CPU. We can however, call printf on the GPU because that function has a special CUDA implementation.
CUDA code otherwise can be any C or C++ code with the following exceptions:
An example of parallel computing that we have seen for Pthreads, OpenMP, and MPI is the partial sum example.
Here, each thread or process is responsible for computing the sum of a range of numbers. Then, each partial sum is added together to make the final answer.
This can be done in CUDA in the following manner:
The following code demonstrates this:
/* sum.cu */
#include <unistd.h>
#include <stdio.h>
#define CORES 16
#define START 0
#define END 100
/* this is the GPU kernel function */
__global__ void sum(int* partials) {
/* find our start and end points */
int start = ((END - START) / CORES) * blockIdx.x;
int end = start + ((END - START) / CORES) - 1;
/* the last core must go all the way to the end */
if (blockIdx.x == (CORES - 1)) {
end = END;
}
/* calculate our part into the array of partial sums */
partials[blockIdx.x] = 0;
int i;
for (i = start; i <= end; i++) {
partials[blockIdx.x] += i;
}
}
/* the main function begins running on the CPU */
int main() {
/* space to store partials on CPU */
int cpu_partials[CORES];
/* allocate space on the GPU for the partial ints */
int* partials;
cudaMalloc((void**) &partials, CORES * sizeof(int));
/* invoke the GPU to run the kernel in parallel
we specify CORES cores which each run once */
sum<<<CORES, 1>>>(partials);
/* copy the partial sums back from the GPU to the CPU */
cudaMemcpy(cpu_partials, partials, CORES * sizeof(int), cudaMemcpyDeviceToHost);
/* free the memory we allocated on the GPU */
cudaFree(partials);
/* now find the final answer on the CPU */
int answer = 0, i;
for (i = 0; i < CORES; i++) {
answer += cpu_partials[i];
}
/* print the final result */
printf("Final answer = %d.\n", answer);
return 0;
}
As we have seen, CUDA __global__ functions may not call CPU functions. The __global__ functions we have seen are simple enough that having them exist as single entities is OK.
However, as our GPU programs get more sophisticated, we will need to split the code into multiple functions.
We can solve this problem with __device__ functions. These are functions that begin with the __device__ keyword which specifies that the function is CUDA code and should be compiled to run on the GPU.
These functions can be called from the __global__ function. They can take any data as parameters, and return any data type as well.
The following example use __device__ functions to split the logic of "islower" and "toupper" out of the hello world example seen last time:
/* hello-functions.cu */
#include <unistd.h>
#include <stdio.h>
#define N 16
#define CORES 16
/* a GPU function for islower */
__device__ int islower(char c) {
return (c >= 'a') && (c <= 'z');
}
/* a GPU function for toupper */
__device__ char toupper(char c) {
return c - 32;
}
/* this is the GPU kernel function */
__global__ void hello(char* s) {
/* blockIdx is a struct containing our block id
if this this is a one-dimensional kernel, then x is the block id
y and z are also available for 2 or 3 dimensional kernels */
int i = blockIdx.x;
/* capitalize the string by capitalizing each lower case letter */
if (islower(s[i])) {
s[i] = toupper(s[i]);
}
}
/* the main function begins running on the CPU */
int main() {
/* this is the string data - it is 'hello world', in lower-case */
char cpu_string[N] = "hello world!";
/* allocate space on the GPU for the string */
char* gpu_string;
cudaMalloc((void**) &gpu_string, N * sizeof(char));
/* send the character array to the GPU */
cudaMemcpy(gpu_string, cpu_string, N * sizeof(char), cudaMemcpyHostToDevice);
/* invoke the GPU to run the kernel in parallel
we specify CORES cores which each run once */
hello<<<CORES, 1>>>(gpu_string);
/* copy the string back from the GPU to the CPU */
cudaMemcpy(cpu_string, gpu_string, N * sizeof(char), cudaMemcpyDeviceToHost);
/* free the memory we allocated on the GPU */
cudaFree(gpu_string);
/* print the string we got back from the GPU */
printf("%s\n", cpu_string);
return 0;
}
In the examples above, we use a one dimensional kernel. CUDA calls our __global__ kernel function once for each of the single items in the array.
It's also possible to use multi-dimensional kernels. This is done by declaring a dim3 variable. This can be used to declare 2-dimensional spaces by passing the two dimensions to the dim3 constructor:
dim3 space(width, height);This declares a variable called "space" which can then be passed to CUDA when launching a kernel:
kernel<<<space, 1>>>Now, the kernel will be called width*height times. Also, the blockIdx variable will have its x and y values set according to which block we are calculating.
This can also be extended to three-dimensional blocks:
dim3 space(width, height, depth);This would be useful for looping through three-dimensional arrays.
The limit on the size of any one dimension is 65,535.
As an example of multi-dimensional kernels, we will look at a program which computes the Julia set.
This is an application of a certain type of function over complex numbers (numbers with a real and imaginary part).
The function applies an iterative process to the values. If they diverge to infinity, they are not in the Julia set. If they remain bounded, they are in the set.
The interesting thing about the Julia set is that, for most values of constants in the function, the set produces chaotic fractals when applied in two dimensions.
The example we will look at applies this function to the X and Y coordinates of an image, and sets the pixel value to be either red if the function returns a 1, or black if the function returns a 0.
Important points of the implementation:
The full code example is below:
/* julia.cu */
#include <stdio.h>
/* size of the image width and height in pixels */
#define SIZE 5000
/* an image is a 2D array of color data */
struct Image {
int width, height;
unsigned char* data;
};
/* function to save the image to a PPM file */
void save_image(struct Image* image, const char* fname) {
/* open the file */
FILE* f = fopen(fname, "w");
if (!f) {
fprintf(stderr, "Error, could not open file '%s' for writing.\n", fname);
return;
}
/* write the magic number, size, and max color */
fprintf(f, "P3\n%d %d\n255\n", image->width, image->height);
/* write the image data */
int i, j;
for (i = 0; i < image->height; i++) {
for (j = 0; j < image->width; j++) {
fprintf(f, "%u ", image->data[i*image->width*3 + j*3 + 0]);
fprintf(f, "%u ", image->data[i*image->width*3 + j*3 + 1]);
fprintf(f, "%u ", image->data[i*image->width*3 + j*3 + 2]);
}
fprintf(f, "\n");
}
/* close the file */
fclose(f);
}
/* a struct for storing complex numbers */
struct Complex {
float r;
float i;
};
/* get the magnitude of a complex number */
__device__ float magnitude(struct Complex c) {
return c.r * c.r + c.i * c.i;
}
/* multiply two complex numbers */
__device__ struct Complex mult(struct Complex a, struct Complex b) {
struct Complex result;
result.r = a.r * b.r - a.i * b.i;
result.i = a.i * b.r + a.r * b.i;
return result;
}
/* add two complex numbers */
__device__ struct Complex add(struct Complex a, struct Complex b) {
struct Complex result;
result.r = a.r + b.r;
result.i = a.i + b.i;
return result;
}
/* the julia function */
__device__ int julia(int x, int y) {
/* translate the point into complex space */
const float scale = 1.5;
float jx = scale * (float)(SIZE / 2 - x) / (SIZE / 2);
float jy = scale * (float)(SIZE / 2 - y) / (SIZE / 2);
/* arbitrary starting point */
struct Complex c;
c.r = -0.8;
c.i = 0.156;
struct Complex a;
a.r = jx;
a.i = jy;
int i;
/* apply the iterative process */
for (i = 0; i < 200; i++) {
a = add(mult(a, a), c);
if (magnitude(a) > 1000) {
return 0;
}
}
return 1;
}
/* the main kernel function runs julia on each pixel */
__global__ void kernel(unsigned char* data) {
/* map from blockIdx to pixel position */
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x;
/* calculate the value at this position */
int julia_value = julia(x, y);
data[offset * 3 + 0] = 255 * julia_value;
data[offset * 3 + 1] = 0;
data[offset * 3 + 2] = 0;
}
/* the main function begins running on the CPU */
int main(int argc, char** argv) {
/* create the image */
struct Image image;
image.width = SIZE;
image.height = SIZE;
image.data = (unsigned char*) malloc(SIZE * SIZE * 3 * sizeof(unsigned char));
/* allocate space for the image data */
unsigned char* gpu_image;
cudaMalloc((void**) &gpu_image, SIZE * SIZE * 3 * sizeof(unsigned char));
/* run the kernel */
dim3 grid(SIZE, SIZE);
kernel<<<grid, 1>>>(gpu_image);
/* copy the data back into the image */
cudaMemcpy(image.data, gpu_image, SIZE * SIZE * 3 * sizeof(unsigned char), cudaMemcpyDeviceToHost);
/* free the GPU memory */
cudaFree(gpu_image);
/* save the image */
save_image(&image, "julia.ppm");
return 0;
}
The output of this program is this (very large) image.
The interesting thing about the Julia set is that the relatively simple function gives very interesting output.
Copyright © 2024 Ian Finlayson | Licensed under a Attribution-NonCommercial 4.0 International License.
{kind=link}