Parallel Hardware
The von Neumann Model
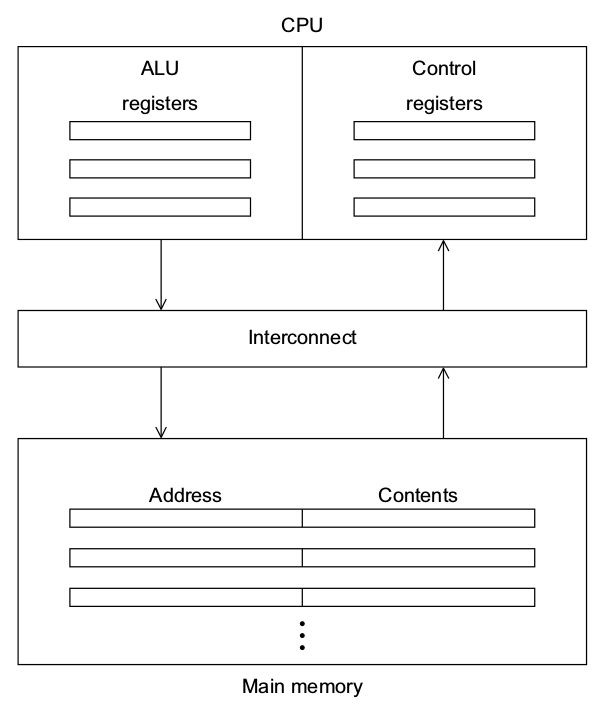
Instruction cycle:
- Read instruction from memory.
- Decode instruction.
- Execute instruction.
- Write results to memory.
The "von Neumann bottleneck" is the interconnect between the CPU and main memory.
Instruction Level Parallelism
Attempts to improve processor performance by having multiple processor components or functional units simultaneously executing instructions.
Pipelining
Overlapping the execution of multiple instructions in different stages.
Multiple Issue
Starting several instructions at the same time.
Instruction level parallelism happens automatically in hardware, it's not what we will be concerned with in this class.
Processes & Threads
A process is an instance of a program being executed. Contains:
- The machine code comprising the program.
- The stack, heap and global space for data.
- Resources allocated for the program (e.g. files).
The main job of the operating system is to run multiple processes concurrently.
A program can also launch extra processes for itself, but each has distinct memory, so sharing of data must be done manually.
Threads are contained within processes. All threads of a process share one address space and can access the same data. All mutual exclusion must be done manually.
Caching
Caches help alleviate the von Neumann bottleneck. They involve one or more levels of memory closer to the CPU.
- The smaller a memory, the faster it is to access.
- The closer a memory is to the chip, the faster it is to access.
Below is an image of the cache layout of an Intel i7 chip:
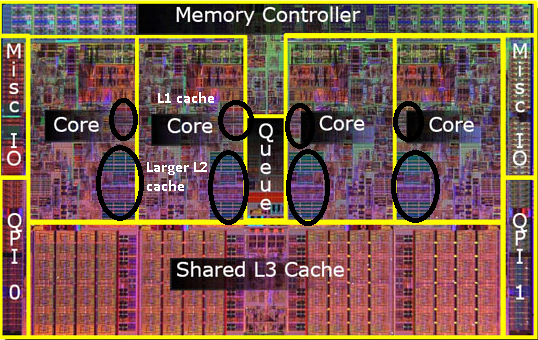
- Each core has its own L1 and L2 caches.
- The L3 cache is shared among 4 cores.
- Main memory is stored off chip.
The following table gives typical sizes and access speeds of cache levels:
| Memory Type | Typical Size | Typical Speed |
| L1 Cache | 32 KB | 4 cycles |
| L2 Cache | 256 KB | 10 cycles |
| L3 Cache | 8 MB | 50 cycles |
| Main Memory | 8 GB | 800 cycles |
When doing a memory access, the following process happens:
- The first level cache is searched.
- If it's not there, the second level cache is searched.
- If it's not there, the third level cache is searched.
- If it's not there, the location is accessed in main memory.
Flynn's Taxonomy
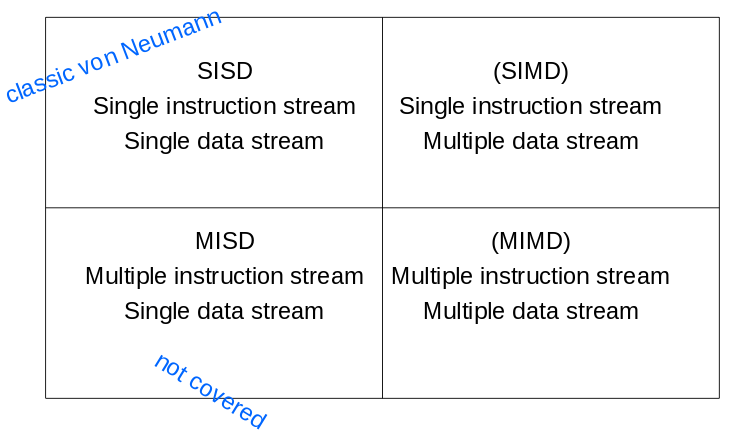
SISD
Single instruction stream, single data stream. This is a traditional, non-parallel computer.
SIMD
Single instruction stream, multiple data stream. We do the same instructions on multiple pieces of data in parallel. GPUs and vector processors are examples of SIMD machines.
MISD
Multiple instruction stream, single data stream. There is not really any common application of doing different sets of instructions on the same data.
MIMD
Multiple instruction stream, multiple data stream. Here, independent processor cores can execute different instructions on independent data streams.
SIMD
- Divides data amongst multiple cores.
- Applies the same instructions to the data.
- Called data parallelism.
Early SIMD machines were called "vector processors".
The idea lives on in GPUs and media processors.
GPUs
Graphics processing units were originally created for rendering graphics quickly. This involves a few common operations:
- Matrix multiplications
- Cross products
- Dot products
These operations also must be applied to large numbers of vertices or pixels, opening up the possibility of data parallelism.
These capabilities are great for many other computational tasks.
GPUs are much different than CPUs:
- Many more cores (solaria has 6144 GPU cores).
- Slower clock speed (usually less than 1 GHZ).
- Less independence amongst cores.
MIMD
MIMD is more general than SIMD as each core can execute different instructions.
MIMD parallel machines are broken down in terms of how memory is accessed:
Shared Memory
- The cores share a memory system.
- Each processor can access every memory space.
- Multi-core laptops and desktops are shared memory systems.
Distributed Memory
- The cores each have their own memory system and communicate over a network.
- They can be physically next to each other (a cluster).
- They can be spread across the world (volunteer computing).
The memory system has a huge impact on how to program the system effectively.
Supercomputers
Supercomputers are large clusters of powerful computer systems that combine shared memory systems which are networked together. The most powerful supercomputer in the world is currently the Frontier system at Oak Ridge National Laboratory in Tennessee, which has 8,730,112 total CPU cores.

Programming Parallel Machines
We will look at two major ways of doing parallel programming:
Multi-Threading
This involves creating multiple threads in one process. It can be used to write programs for shared memory systems, and makes sharing data easy.
Multi-Processing
This involves creating multiple processes. It can be used to write programs for shared memory or distributed memory systems, and sharing data must be done more explicitly.