We have shown that any regular expression can be converted into a finite automata. Now we will prove the opposite, that any finite automata can be converted into a regular expression.
First we will need a new type of finite automata, the Generalized Nondeterministic Finite Automata.
A GNFA is an NFA where each transition can have arbitrary regular expressions as labels rather than just elements of $\Sigma$.
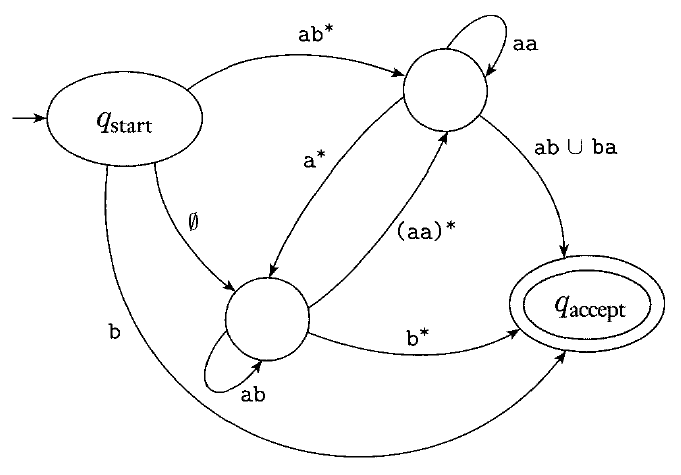
GNFAs can consume multiple input symbols on each transition.
We also require GNFAs follow these rules:
These rules will make the conversion simpler.
To convert a DFA into a GNFA we follow these steps:
How would we convert the following DFA into a GNFA?
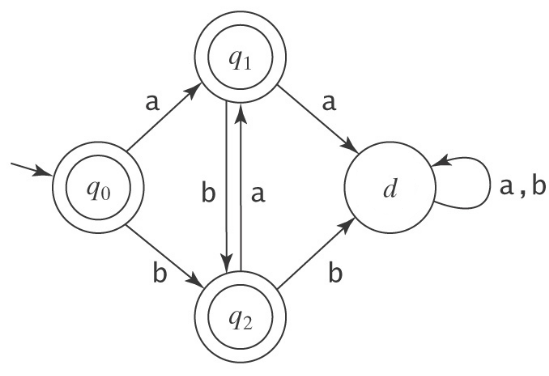
Now we need to convert the GNFA into a Regular Expression.
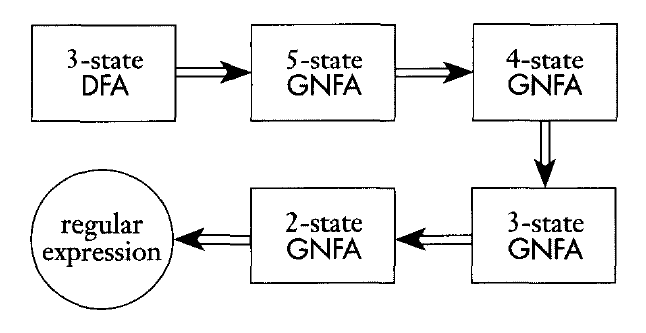
This is done by removing the states of the GNFA one at a time until only the start and accept states remain. The label on the transition from the start state to the accept state will be our regular expression:
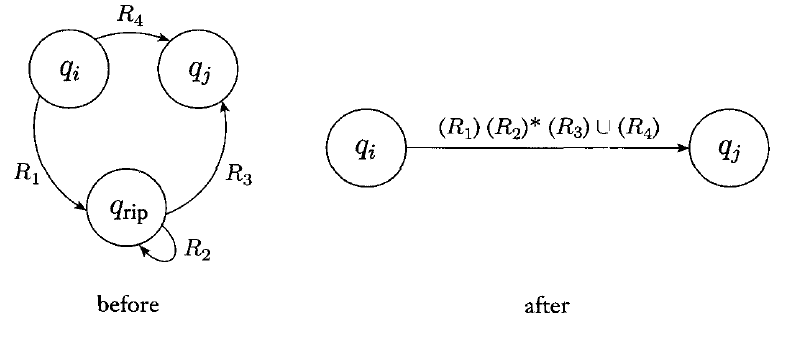
We can do this by choosing any state, ripping it out, then repairing the transitions so that the machine functions the same as before.
Formally: we can define a GNFA as:
Below is an illustration:
How could we convert this DFA into a regular expression?
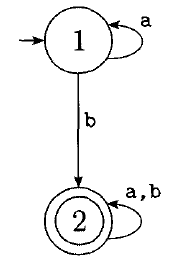
How could we take this more complex DFA all the way to a regular expression?
We now have three ways to talk about regular languages:
All three are equivalent.
Next we will discuss languages that are not regular and thus have no finite automata recognizing them, or regular expression producing them.
Copyright © 2024 Ian Finlayson | Licensed under a Attribution-NonCommercial 4.0 International License.