GPU Architecture
GPUs are quite different from CPUs. Today we will take a more detailed look at GPU architectures, and talk about GPU performance.
Below is a diagram of a typical GPU:
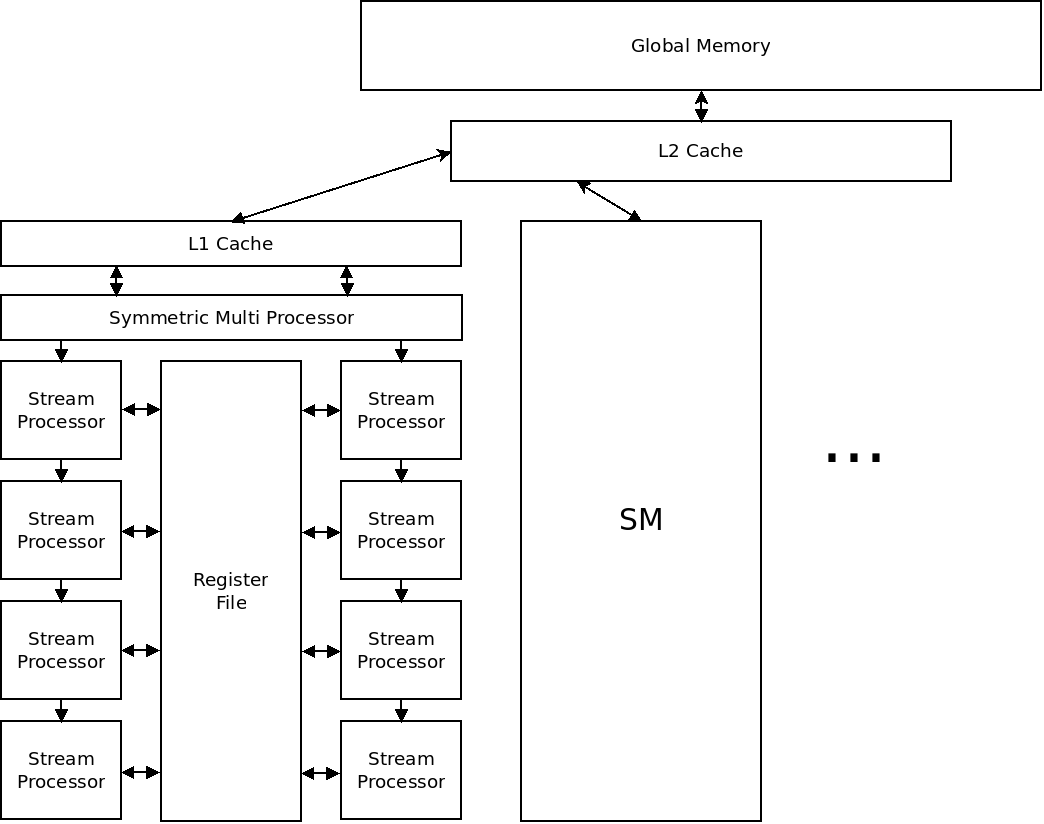
GPUs contain some amount of global memory. They are broken into groups of Symmetric Multi-processors (SMs) which share a cache.
Each SM contains a register file for storing data, as well as several stream processors (SPs). SPs are used for chaining operations together.
The exact number of SMs and SPs, and the number and size of caches varies greatly between GPUs. solaria's GPU has 2 SMs with 1536 SPs each.
All of the SPs in one SM run the same set of instructions. The basic idea is that hundreds or thousands of these stream processors can work together on massively parallel tasks.
GPU Conditionals
Because GPUs are SIMD machines, all cores in a group must execute exactly the same instructions, conditional statements (if, else, swtich) present a problem.
In the code below, there is an if/else statement:
if ((x % 2) == 0) {
x /= 2;
} else {
x = 3 * x + 1;
}
On a GPU, if there are multiple cores in a group executing this code, they cannot take different paths through this code!
The way NVIDIA GPUs solve this problem is with conditional execution. In actual fact, the GPU will execute both statements on all cores. It will just only save the results of some instructions.
GPUs have a register (which we'll call "commit") which determines whether instructions have any effect. If commit is 1, the GPU functions as normal. If commit is 0, the GPU will throw away all computation results.
The code that is actually executed is equivalent to this:
commit = (x % 2) == 0;
x /= 2;
commit = !commit;
x = 3 * x + 1;
commit = 1;
This allows the GPU to have all cores in a group execute exactly the same set of instructions.
The downside is that the cores will be doing extra work. GPU performance typically is not great for code with many branches.
What GPUs are Good At
GPUs are very different from CPUs. The following type of program works well on GPUs:
- Massively parallel tasks.
- Numerical.
- Iterative.
- Long-running kernels.
What GPUs are Bad At
- Single-threaded execution.
- Recursion.
- Branch-heavy code.
- Short-running kernels.
Performance Example
The following C program estimates the Zeno's series:
$\sum\limits_{n=1}^{\infty} \frac{1}{2^n} = \frac{1}{2} + \frac{1}{4} + \frac{1}{8} + ...$
#include <stdio.h>
#include <stdlib.h>
/* N is 1 billion */
#define N 1000000000
/* estimate the sum of 1/2 1/4 1/8 ... 1/2^N etc. */
double est() {
double result = 0.0;
int i;
double denom = 2.0;
for (i = 1; i <= N; i++) {
result += (1.0 / denom);
denom *= 2.0;
}
return result;
}
int main() {
double result = est();
printf("The sum = %lf\n", result);
return 0;
}
We can compare this to a CUDA version:
#include <stdio.h>
#include <stdlib.h>
/* N is 1 billion */
#define N 1000000000
/* we make 1 thousand threads which each calculate 1 million items */
#define THREADS 1000
#define ITEMS (N / THREADS)
/* estimate the sum of 1/2 1/4 1/8 ... 1/2^N etc. */
void __global__ est(double* r) {
double __shared__ results[THREADS];
int i;
double result = 0.0;
double denom = pow(2.0, (double) (threadIdx.x * ITEMS + 1));
for (i = 0; i < ITEMS; i++) {
result += (1.0 / denom);
denom *= 2.0;
}
/* write ours */
results[threadIdx.x] = result;
__syncthreads();
/* now do the sum reduction */
i = THREADS / 2;
while (i != 0) {
/* if we are not thread 0 */
if (threadIdx.x < i) {
/* add the one to our right by i places into this one */
results[threadIdx.x] += results[threadIdx.x + i];
}
/* cut i in half */
i /= 2;
__syncthreads();
}
*r = results[0];
}
int main() {
double result, *gpu_result;
cudaMalloc((void**) &gpu_result, sizeof(double));
est<<<1, THREADS>>>(gpu_result);
cudaMemcpy(&result, gpu_result, sizeof(double), cudaMemcpyDeviceToHost);
printf("The sum = %lf\n", result);
return 0;
}
This program works by using 1,000 CUDA threads to each calculate a portion of the sequence, then use a reduction to compute the final sum.
How does the performance compare to the CPU program? What if we changed it so that it ran 100 threads? 10? 1?
Conclusion
The architecture of a GPU is quite different from that of a CPU. This leads to different performance characteristics. Writing a GPU program requires careful thought as only certain types of programs benefit from a GPU.