OpenMP Synchronization
Overview
We have seen the #pragma omp critical directive which allows us to specify critical sections that can only be entered by one thread at a time.
Today we will look at some additional OpenMP directives which allow us to synchronize and communicate amongst threads.
Critical Sections
Recall that critical sections are introduced in OpenMP with the critical directive:
#pragma omp critical
{
/* critical section here */
}
This is an anonymous critical section. OpenMP will only allow one thread into this critical section at one time.
There is another usage of OpenMP critical sections wherein we have multiple critical sections that all must be preserved.
For example, if we have some data that is written in multiple places in our program:
int global_data;
...
/* write in one location */
global_data++;
...
/* write in another location */
global_data--;
Clearly, we do not want one thread to increment and another to decrement at the same time. The following approach will not work:
int global_data;
...
/* write in one location */
#pragma omp critical
global_data++;
...
/* write in another location */
#pragma omp critical
global_data--;
We can link the two critical sections with a named critical section:
int global_data;
...
/* write in one location */
#pragma omp critical (global_data_lock)
global_data++;
...
/* write in another location */
#pragma omp critical (global_data_lock)
global_data--;
This causes OpenMP to enforce the rule that only one thread can be in either critical section at a time.
Atomic Operations
If, as in the example above, our critical section is a single assignment, OpenMP provides a potentially more efficient way of protecting this.
OpenMP provides an atomic directive which, like critical, specifies the next statement must be done by one thread at a time:
#pragma omp atomic
global_data++;
Unlike a critical directive:
- The statement under the directive can only be a single C assignment statement.
- It can be of the form: x++, ++x, x-- or --x.
- It can also be of the form x OP= expression where OP is some binary operator.
- No other statement is allowed.
The motivation for the atomic directive is that some processors provide single instructions for operations such as x++. These are called Fetch-and-add instructions.
As a rule, if your critical section can be done in an atomic directive, it should. It will not be slower, and might be faster.
Barriers
Recall that a barrier is a point in code where we want all threads to reach before continuing on:
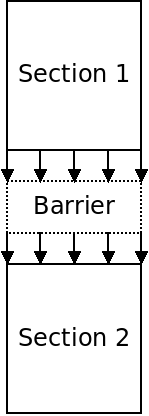
The following OpenMP program spawns a number of threads. How could we add a barrier in the middle of the function?
#include <unistd.h>
#include <stdlib.h>
#include <omp.h>
#include <stdio.h>
#define THREADS 8
/* the function called for each thread */
void worker() {
/* get our thread id */
int id = omp_get_thread_num();
/* we start to work */
printf("Thread %d starting!\n", id);
/* simulate the threads taking slightly different amounts of time by sleeping
* for our thread id seconds */
sleep(id);
printf("Thread %d is done its work!\n", id);
/* TODO make a barrier */
printf("Thread %d is past the barrier!\n", id);
}
int main() {
/* have all the threads run worker */
# pragma omp parallel num_threads(THREADS)
worker();
return 0;
}
This is easily accomplished with OpenMP:
#include <unistd.h>
#include <stdlib.h>
#include <omp.h>
#include <stdio.h>
#define THREADS 8
/* the function called for each thread */
void worker() {
/* get our thread id */
int id = omp_get_thread_num();
/* we start to work */
printf("Thread %d starting!\n", id);
/* simulate the threads taking slightly different amounts of time by sleeping
* for our thread id seconds */
sleep(id);
printf("Thread %d is done its work!\n", id);
/* a barrier */
#pragma omp barrier
printf("Thread %d is past the barrier!\n", id);
}
int main() {
/* have all the threads run worker */
# pragma omp parallel num_threads(THREADS)
worker();
return 0;
}
The barrier directive causes OpenMP to insert a barrier at that point.
Ordered Sections
Suppose we wanted one portion of our threaded code to execute in thread order. This is often desirable for output as it is typically non-deterministic.
The following program may execute in thread order, but probably will not:
#include <stdlib.h>
#include <omp.h>
#include <stdio.h>
#define THREADS 16
/* the function called for each thread */
void worker() {
/* get our thread id */
int id = omp_get_thread_num();
printf("Thread %d says hello!\n", id);
}
int main() {
int i;
#pragma omp parallel for num_threads(THREADS)
for (i = 0; i < THREADS; i++) {
worker();
}
return 0;
}
There is also a built-in directive in OpenMP for this, the ordered directive. The following program uses this:
#include <stdlib.h>
#include <omp.h>
#include <stdio.h>
#define THREADS 16
/* the function called for each thread */
void worker() {
/* get our thread id */
int id = omp_get_thread_num();
#pragma omp ordered
printf("Thread %d says hello!\n", id);
}
int main() {
int i;
#pragma omp parallel for num_threads(THREADS) ordered
for (i = 0; i < THREADS; i++) {
worker();
}
return 0;
}
There are a few restrictions on the ordered directive:
- It can only appear in a parallel for loop - not a parallel block.
- The parallel for loop must be marked as ordered.
This is so OpenMP knows how many threads will be entering the ordered block.