Cache Systems
Overview
The "von Neumann bottleneck" is the interconnect between the CPU and main memory.
Caches help alleviate the von Neumann bottleneck. They involve one or more levels of memory closer to the CPU.
- The smaller a memory, the faster it is to access.
- The closer a memory is to the chip, the faster it is to access.
Modern computers have multiple levels of caches to give a trade-off between speed and size.
The basic idea behind a cache is that when we load data, we pull it into the cache system. Then if we need to load it again (or the data next to it), we can do so more quickly next time. This is based off the following principles:
Principle of temporal locality
If we access a variable in a program, we're pretty likely to need to access it again soon.
Principle of spatial locality
If we access a variable in a program, we're pretty likely to need to access the ones next to it soon.
These two principles hold for nearly all programs. This means that after loading one memory location into the cache, we usually get lots of reads done more quickly afterwards.
Cache Lines
Data is stored in a cache in lines which are 64 bytes on modern x86 systems. Notice that 64 bytes holds more than one variable. This means several variables will be packed together in one cache line. Each line also stores a tag and flags:
| tag | line data | flags |
The tag indicates which address range the cache line is holding. This is used to check whether the address we want is in the cache or not.
The flags store meta-data about the cache line such as when it was most recently accessed. This allows the cache system to replace the oldest lines when new data is being brought in. The flags also include whether the data has been modified since being loaded into the cache.
Cache Operation
When a program tries to access a piece of data from a cache, it searches for the tag indicating the memory address. If found, it returns it back.
If not found, it is pulled in from a lower level cache (or possibly main memory). However, when something is pulled into the cache, something else must be removed to make room. This is called a cache eviction.
Caches typically use the cache lines flags to try to evict a line which has not been used recently.
Even when not doing parallel programming, we sometimes need to be aware of caches to write efficient programs. Consider the following two java programs which loop through two-dimensional arrays:
The second version of this program will run much more quickly than the first. Why is that?
Writing Policy
Remember that if something is stored in the smallest cache, it is also stored in all of the other caches and main memory. If a piece of data in a cache is modified, what should be done with the corresponding entires?
There are two schemes for this:
- Write Through: All copies of a piece of data are immediately written into the lower memories.
- Write Back: Lines that are written are marked "dirty" and are only written back on eviction.
The second scheme will be more efficient, but does it work with multiple threads?
Cache Coherence
In a multi-core setup, caching can cause additional issues. What happens if two processors both have a copy of the same value in private caches:
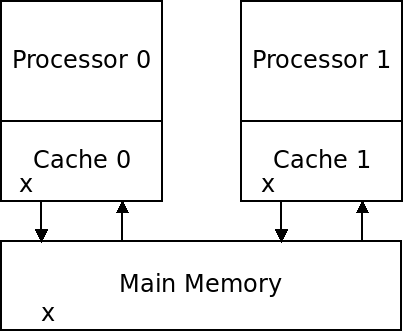
What if both processors write to their copy of x?
Which one should be written back to main memory?
A cache coherence policy attempts to manage these conflicts.
Approaches to cache coherence include:
Invalidation
If a processor writes a value, other copies of it in other caches are marked as being invalid. Future reads of them must go to a higher-level structure.
Update
When a processor writes a value, other copies of it are updated from the old value.
What are the trade-offs between these approaches?
Both of these incur a performance penalty. Even without synchronization, sharing data between threads can result in large performance degradation.
False Sharing
Cache coherence slowdowns can affect us even if we do not write to the same locations.
Consider the following structure:
struct Item {
int x;
int y;
};
If two threads access the same object, but one thread only accesses the "x" member, while another only accesses the "y" member, there should be no issue.
However, the cache only works with entire lines. This entire object will easily fit into one cache line, so both threads will write to the same cache line, causing the cache to maintain coherence.
This can also happen with arrays. For example if we have a small array that fits in a cache line, and each thread uses a separate element, we will have false sharing. It can also happen with local variables in main's stack. Stack entries are stored contiguously and so if we give each thread a pointer to a variable on main's stack we will likely have false sharing as well.
The solution is to make sure that the memory locations your threads will use (in loops at least) are spread out. Thread's private stacks and locations obtained separately from the heap are best.
Understanding the cache is necessary to write efficient code — especially in a parallel environment.