Programming Safety
Overview
Programming safety refers to different constructs for ensuring that programs can handle errors reliably. Different languages provide different ways to respond to errors.
Also, different languages are susceptible to different kinds of errors.
Assertions
Assertions are a simple error testing construct available in many languages. An assertion is a programming statement that includes a condition. If that condition is true, the assertion does nothing. If it's false, the program is terminated with an error.
#include <assert.h>
#include <stdio.h>
int divide(int a, int b) {
assert(b != 0);
return a / b;
}
int main() {
int x, y;
scanf("%d %d", &x, &y);
printf("%d\n", divide(x, y));
return 0;
}
If the user enters a non-zero denominator, the assertion does nothing. If they enter 0, this error is produced:
a.out: x.c:5: divide: Assertion `b != 0' failed.
zsh: abort (core dumped) a.out
Assertions produce messages from the source code including the filename, line and condition text. That is not usually possible in compiled languages. In C, assert is actually a macro that is replaced by the pre-processor. The assertion above becomes:
((b != 0) ? (void) (0) : __assert_fail ("b != 0", "x.c", 5, __PRETTY_FUNCTION__));
Assertions can also be turned off globally in C by defining the symbol "NDEBUG". That is done for performance reasons once the code is debugged.
Assertions can also be used in most other programming languages with the same concept.
Simple Error Handling
A simple way to handle errors, especially in languages like C is to use return values from functions. Many libraries, like MPI, have functions actually return data through parameters and use the return value for an error code.
This can lead to code like the following:
int function() {
if(functionA(...) == ERROR) {
// handle the error
}
if(functionB(...) == ERROR) {
// handle the error
}
if(functionC(...) == ERROR) {
// handle the error
}
}
The error handling code can become more prominent then the actual logic of the program.
setjmp/longjmp
Ideally we could write our code without littering it with error checking code and handle the errors all in one spot.
One way to achieve this in C is with the setjmp and longjmp functions. These are used to jump to an arbitrary location in code.
The following example demonstrates the use of these functions:
#include <stdio.h>
#include <setjmp.h>
jmp_buf buf;
void function1(int x) {
printf("Function1 called, x = %d.\n", x);
if(setjmp(buf) == 0) {
printf("We just set the jump.\n");
} else {
printf("We just jumped here from longjmp (x = %d)!\n", x);
}
printf("Function1 returning.\n");
}
void function2() {
/* go to the setjmp location and pass a 1 */
printf("Jumping!\n");
longjmp(buf, 1);
}
int main() {
printf("Main starting.\n");
function1(10);
function2();
printf("Main ending.\n");
return 0;
}
longjmp can be used to jump across the program arbitrarily. However, it does not unwind the stack at all. This means local variables may not be correct after executing the jump.
These functions are used to simulate exceptions in C:
void functionA() {
/* ... */
if(error)
longjmp(buf, 1);
}
void functionB() {
/* ... */
if(error)
longjmp(buf, 2);
}
void functionC() {
/* ... */
if(error)
longjmp(buf, 3);
}
int function() {
/* we can ignore errors now */
functionA();
functionB();
functionC();
}
int main() {
if(setjmp(buf) == 0) {
function();
} else {
/* handle errors here */
}
}
The longjmp essentially works as a "throw", the call to setjmp as a "try", and the else portion above as a "catch".
Exceptions
Exception handling was created as a more robust way to handle this situation. Languages such as Python and Ruby (which are implemented in C) use setjmp/longjmp under the hood to implement exceptions.
There are typically three parts of an exception:
Try
Specifies a block of code in which an exception might occur. Code in the try block is executed until an exception happens.
Catch
Specifies a block of code to handle an exception in some way. Code in the catch block is only executed on an exception.
Throw
Creates a new exception, and transfers control to the nearest catch block that can be found. Exceptions can only be caught by a catch matching its type.
As an example:
int divide(int a, int b) {
if(b == 0) {
throw DivideByZero();
}
return a / b;
}
int main() {
int a, b;
cin >> a >> b;
try {
cout << divide(a, b);
}
catch(DivideByZero e) {
cout << "You can't divide by zero!";
}
}
Notice that the exception is caught by a catch in a different function. When an exception is thrown, the program returns from multiple functions searching for a matching catch. This is called stack unwinding.
Because stack unwinding is done, we can reference local variables inside of exception handlers.
Exception Types
In the example above, the exception type we threw was DivideByZero. When it comes to match the exception, the system finds the best match. This integrates with inheritance.
If there is a catch that handles a base class, it will match a base class. Languages like Java create class hierarchies of errors:
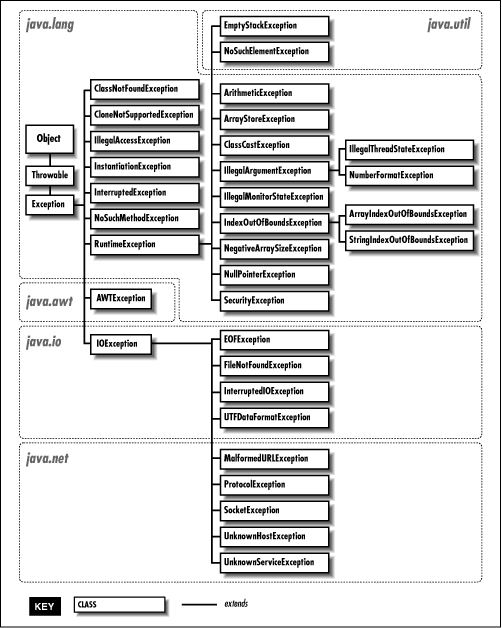
This allows programmers to catch a generic exception like "RuntimeException" or "IOException" and catch any derived class.
We can also make new exceptions for errors we may create to integrate with existing errors.
finally
Throwing exceptions can lead to problems where resources are not cleaned up:
public static void main(String[] args) {
try {
// open a file
BufferedReader in = new BufferedReader(new FileReader(filename));
// read from the file (can create an exception)
String input = in.readLine();
// close the file
in.close();
} catch(IOException e) {
// when we get here, the file may not have been closed
in.close();
}
}
Rather than have to repeat this code, we can use a "finally" block in Java which will always execute regardless of whether or not an exception occurred:
public static void main(String[] args) {
try {
// open a file
BufferedReader in = new BufferedReader(new FileReader(filename));
// read from the file (can create an exception)
String input = in.readLine();
// don't close the file here
} catch(IOException e) {
// handle the error
} finally {
// this will always execute
in.close();
}
}
The finally block is executed even if the code in the try throws an uncaught exception or returns. The finally block allows reduction in redundant code.
Static Program Analysis
Catching errors statically is better than catching them dynamically. Dynamic languages such as Python suffer from not being able to catch as many static errors. There are software tools to help with this.
The code below:
def fact(x):
if x < 2:
return 1
else:
return x * fact(x - 1)
x = int(input("Enter number: "))
if x < 0:
printf("Error, enter a positive number")
else:
print("factorial =", fact(x))
Has an error in it. The call to "printf" should be "print". This error can go undetected until we actually test that code path.
Static analysis tools such as pychecker or pyflakes can catch this type of error:
> pyflakes x.py
x.py:11: undefined name 'printf'
Even static languages like C, C++ or Java can benefit from static analysis tools.
An early tool to check C code is lint. For the following code:
#include <stdio.h>
#include <stdlib.h>
int* getValue() {
int x = 10;
return &x;
}
int main() {
int* a = getValue();
int* b = malloc(sizeof(int));
int nums[10];
while(1) {
if(a = 0) {
nums[10] = 1;
}
}
return 0;
}
x.c: (in function getValue)
x.c:6:10: Stack-allocated storage &x reachable from return value: &x
A stack reference is pointed to by an external reference when the function
returns. The stack-allocated storage is destroyed after the call, leaving a
dangling reference.
x.c:16:8: Fresh storage a (type int *) not released before assignment: a = 0
A memory leak has been detected. Storage allocated locally is not released
before the last reference to it is lost.
x.c:16:8: Test expression for if is assignment expression: a = 0
The condition test is an assignment expression. Probably, you mean to use ==
instead of =. If an assignment is intended, add an extra parentheses nesting
(e.g., if ((a = b)) ...) to suppress this message.
x.c:21:10: Unreachable code: return 0
This code will never be reached on any possible execution.
x.c:12:8: Variable b declared but not used
A variable is declared but never used. Use /*@unused@*/ in front of
declaration to suppress message.
x.c:17:7: Likely out-of-bounds store: nums[10]
Unable to resolve constraint:
requires 9 >= 10
needed to satisfy precondition:
requires maxSet(nums @ x.c:17:7) >= 10
A memory write may write to an address beyond the allocated buffer.
There are many tools like this available for popular languages.
Unfortunately there is no general way to write a program that can detect all coding errors. Rice's theorem states that no non-trivial property of an algorithm can be proven in general. Tools like lint cannot guarantee that they will detect any errors, though in many practical cases they can.