Lexical Analysis
Overview
Lexical analysis is the process of breaking a program into lexemes. A lexeme is a single, indivisible unit in a program.
For example, the following code:
for (int i = 0; i < 10; i++) {
// some comment here
array[i] = array[i] + 2.5;
}
- for
- (
- int
- i
- =
- 0
- ;
- i
- <
- 10
- ;
- i
- ++
- )
- {
- array
- [
- i
- ]
- =
- array
- [
- i
- ]
- +
- 2.5
- ;
- }
Lexemes come in different types called tokens. Tokens include identifiers, reserved words, numbers, strings and symbols.
Common Tokens
Identifiers are one of the most common tokens in programs. They are typically composed of ASCII letters, numbers and underscores.
Languages have different rules regarding the form of valid identifiers. C, C++, Ruby and Python use the following rules:
- The first character must be an underscore or a letter.
- Each subsequent character must be an underscore, letter or digit.
Java also allows dollar signs to be included.
Haskell allows single quotes.
LISP languages allow hyphens, question marks and more.
Keywords are the words in a program that have a special meaning such as "if", "while", "throw" etc.
Reserved words are words that cannot be used as identifiers names. In most modern languages, they are the same thing.
Numbers are another token. Most languages have similar rules about numbers in programs. Integers are simply written as a sequence of digits. Floating point numbers are written using a decimal point or scientific notation.
C and C++ also allow trailing letters to signify the data type of the constant. They also allow for octal and hexadecimal values. The following are all valid numeric constants in C:
| 42 | decimal |
| 052 | octal |
| 0x2A | hex |
| 42L | long int |
| 42LL | long long int |
| 42.0 | double |
| 42.0f | float |
| 4.2e10 | scientific |
| 4.2e10f | scientific float |
The lexical analyzer must be able to recognize every representation for these.
Comments are also handled by the lexer. Different languages have different rules for how comments look. Some have a start symbol and end symbol such as /* and */ in C. Others have only a start symbol and go through the end of the line such as // in Java and # in Python.
Older languages tended to use keywords for comments instead of symbols such as the "REM" in BASIC or "C" in FORTRAN.
Comments with begin and end symbols typically have issues with nested comments.
Strings are typically enclosed in " or ' characters, and contain characters in between.
Perl has two different types of string literals. Strings in single quotes are taken verbatim, while strings in double quotes are interpolated.
Other types of tokens include arithmetic and logic operators:
+ - * / % & | ^ ~ ! <...
() [ ] { } begin end...
Lexical analysis often ignores whitespace, but there are some cases where it is important. In Python, indentation is used to control blocks instead of braces. To implement this, a lexer must keep track of the indentation level and insert extra INDENT and DEDENT tokens.
Writing a Lexer
There are two ways to write a lexer:
- By hand, creating a state machine that reads one symbol at a time, deciding it has read a token when one is completed.
- Using a lexer generator, and providing regular expressions for the tokens you need.
In this class, we will use the ANTLR system which provides both lexer and parser generators. We will look at parsers next week, but use ANTLR for lexer generation now.
ANTLR Setup
ANTLR is installed on the CPSC server, but you must add it to your
CLASSPATH environment variable. This variable tells the Java
virtual machine where to look for classes that are referenced. Since our
programs will rely on ANTLR classes, we need to tell the JVM where to find them.
To do this, put the following into your .bash_profile file:
export CLASSPATH=".:/usr/local/lib/antlr-4.13.1-complete.jar:$CLASSPATH"
We also will make aliases for running the ANTLR tool and test program. This will
allow us to invoke these classes from the command-line more conveniently. Add this
to the .bash_profile as well:
alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.13.1-complete.jar:$CLASSPATH" org.antlr.v4.Tool'
alias grun='java -Xmx500M -cp "/usr/local/lib/antlr-4.13.1-complete.jar:$CLASSPATH" org.antlr.v4.gui.TestRig'
We should now be set up to use both the ANTLR tools and runtime library!
Regular Expressions
Regular expressions, or "regexes" are patterns which match sequences of text. There are many slightly different sytaxes for them. Here we will talk about the regex patterns allowed in ANTLR:
- Any string of text is a regex matching exactly that text. ANTLR uses single quotes
to contain text. For instance, the regex
'while'matches the keyword "while" and nothing else. - If multiple characters are inside of square brackets, any of them can be matched. For
example
[+-*/]would match any of those 4 operators and[aeiou]would match any vowel. - Ranges of characters can be created using brackets as well. For example
[0-9]matches any single digit and[a-zA-Z]matches any letter. - Any two regular expressions can be combined with the | bar, which will allow either pattern
to be matched. For example the regex
'+' | '-'will match either a plus or minus sign. - A * can be appended to an regex to match zero or more copies of it. For example
a*matches "", "a", "aa", "aaa", etc. The regex[0-9]*matches any string of digits (including zero digits). - Similarly a + can be appended to match one or more copies. For example
[0-9]+matches any string of digits, but enforces that at least one must exist. - By adding a ? to the end of a regex, we indicate either 0 or 1 instances of it. For example,
the regex
'-'?[0-9]+matches a string of digits which may or may not begin with a negative sign. - The ~ character negates the regex following it. So
~'"'matches any character except for a double quote and~[A-Z]matches anything except for a capital letter. - Regex can be grouped with parentheses to ensure the operators happen the way we want.
For instance
('a' | 'b')*will match any strings of the letters a and b. On the other hand'a' | 'b'*will match either a single a, or any string of b's.
Calculator Example
ANTLR lexers are created by making a .g4 file, containing lexer rules. These lexer rules contain the name of the token being matched (which must begin with a capital letter), followed by a colon. Next comes a regular expression giving the pattern to match, and finally a semi-colon.
The calculator lexer example contains lexical rules for matching floating point numbers, and a few symbols needed to write a calculator program:
lexer grammar CalculatorLexer;
PLUS: '+';
MINUS: '-';
DIVIDE: '/';
TIMES: '*';
LPAREN: '(';
RPAREN: ')';
PI: 'pi' | 'PI';
DONE: '\n';
REALVAL: '-'?[0-9]*'.'?[0-9]+;
WS: [ \t]+ -> skip;
Notice that the symbols are all defined with a regular expression matching a single character. The "PI" symbol matches the text "pi" or "PI".
The only really complex regular expression in this lexer is the "REALVAL" token which matches:
- An optional negative sign
- Zero or more of the symbols [0-9]
- An optional decimal point
- One or more of the symbols [0-9]
Also notice the -> skip. This tells ANTLR not to actually produce
the WS token in the token stream, but simply discard it. This is done for whitespace
here and is also typically done for comments in program code.
How ANTLR Works
There are algorithms for transforming regular expressions into a computing structure called a "finite state machine". An FSM keeps track of what state we are in, and makes a transition to a new state for each character read. Below is a state machine recognizing an identifier using C rules:
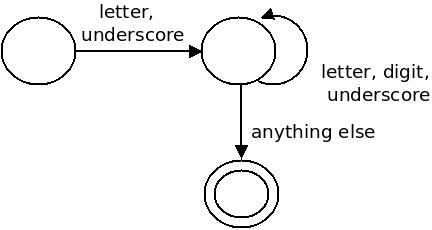
Each new character takes us into another state. When we reach a state that marks the end of one of our tokens, we produce that lexeme and pass it along to the parser. The basic idea behind the algorithm is:
- Concatenation of multiple regexes is given as sequential states.
- If we have an or, we have multiple regexes combined with an |, we allow multiple symbols to give the same transition.
- Repetition is given as a transition back to the same state.
ANTLR uses this algorithm to transform our regexes into a Java class containing an FSM which recognizes the lexemes in our language. This is easier and more maintainable than writing the lexer by hand.