Prim's Algorithm
Minimum Spanning Trees
A spanning tree is a tree that is made by selecting a subset of the edges of a graph such that all of the nodes of the graph are in the tree. The tree must also be a tree, so there can be no cycles in it. Below is a spanning tree for the cities graph:
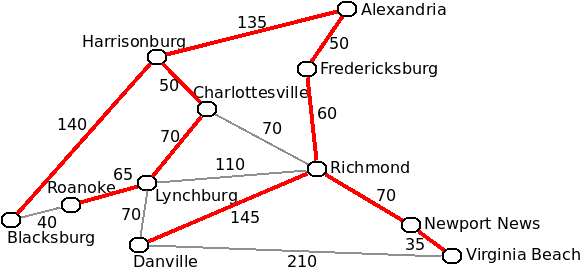
Which node is considered to be the root is not important when discussing spanning trees. There can be multiple spanning trees for any one graph. The minimum spanning tree is the one for which the sum of the weights in the tree has the least value. Also note that only a connected graph can have a spanning tree.
There are several applications of minimal spanning trees. For example if an electric company wished to supply electricity for each of the above cities, running power lines along the edges of the minimal spanning tree will be use the least amount of cable.
The Algorithm
There are several algorithms to solve this problem, one we will talk about is Prim's algorithm. Prim's algorithm starts with an empty minimal spanning tree. It then adds any one node to the tree. Then it repeatedly adds one node and one edge to the graph until it has a minimal spanning tree. Each time through it chooses the edge that connects a node in the tree with one not yet in the tree. If there are several, it chooses the one with the least weight.
The best way to implement this is with a min-heap to store the edges that can be added to the tree. Below is pseudocode for this algorithm:
- Create an empty graph for the MST
- Create an empty min-heap of edges
- Keep track of which nodes are in the MST, set all to false
- Choose a node to add to the MST first
- Add all of this node's outgoing edges to the heap
- While the MST isn't done:
- Dequeue the next edge from the heap
- If the destination of this edge is already in the tree, discard it
- Put the edge and its destination in the MST
- For each edge of the node we just added:
- If the other side of this edge isn't in the MST, add the edge to the heap
- Return the now finished MST
This example implements Prim's algorithm. The minimal spanning tree that is actually found for this graph is depicted below:
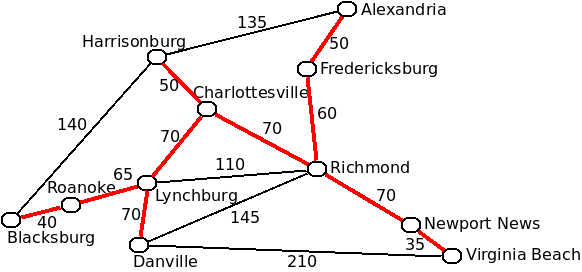
Analysis
Like Dijkstra's algorithm the analysis for Prim's algorithm depends on how it was implemented. In the example code above, we used a heap for storing the edges and an incidence list for the graph.
As you might expect, the loop dominates the algorithm's running time (step 6 in the pseudocode). This loop will execute roughly $V$ times, because it adds a node to the tree each time.
Step 6.1 takes $\log E$ time because of the use of the heap to store edges. 6.2 and 6.3 are constant time operations.
The nested for loop iterates for each edge of the node we are looking at. The average node has $\frac{E}{V}$ edges (because there are $E$ edges and $V$ nodes total). And inside this loop, we insert into the heap which is $\log E$ again.
Putting this together we have:
$V \times (\log E + \frac{E}{V}\log E)$
The first $V$ is the iterations of the while loop. The first $\log E$ is our dequeue from the heap. The $\frac{E}{V}$ is the iterations of the for loop. And the last $\log E$ is the insertion into the heap.
By distributing the outer multiplication, we can simplify this expression to:
$V\log E + E\log E$
For this application, $E$ will always be at least as big as $V - 1$. If that's not true then their must be some nodes with no edge connections. And in that case, we can't make a MST in the first place.
So because $E > V$, we can take only the second term and say this algorithm is $O(E\log E)$.