Heaps
Overview
A queue is a data structure for storing elements in a first-in-first-out manner. So we will remove items in the same order that they came in.
In some applications, however, we may want to allow elements to skip others in some situations, such as task scheduling.
Another use of priority queues is when we want to choose from among a set of objects based on some metric. For example, in Prim's algorithm, we choose edges with the smallest weight, and in Dijkstra's we choose nodes with the least current tentative cost.
In a priority queue, we assign each object a priority, and when it comes time to take an object from the queue, we take the one with the highest priority. If there are multiple at the same priority level, we will take the oldest (using FIFO).
We could use an array or linked list to implement a priority queue. To insert an object into the queue, we will add it to the end. Then to remove one, we will scan through searching for the oldest one with the highest priority level.
A more efficient implementation is based on a heap.
Heaps
A heap is a type of binary tree where each node's value is greater than or equal to the value of each of its children. Heaps are also perfectly balanced with the nodes in the last level in the leftmost positions. The following is an example of a heap:
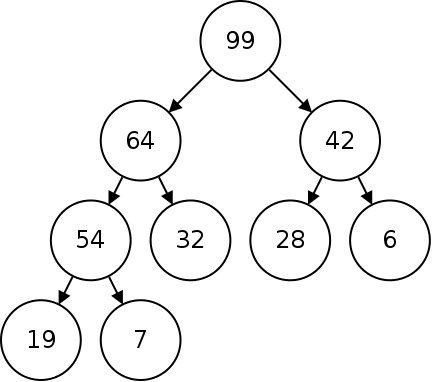
This heap is called a max heap because the root node is the maximum. We could also have a min heap where each node's value is less than or equal to that of its children.
Here we will only talk about max heaps, though the same ideas apply to min heaps as well.
Using a heap to represent a priority queue, we will always take the root item next as this is the one with the largest priority.
Notice that there is no particular relationship between sibling nodes, the only relationship that matters is the parent to the child.
Operations
Heaps support a number of different operations:
- Creation - Create an empty heap.
- Insert - Add an element to the heap.
- Next - Return the root element.
- Remove - Remove the root element from the heap.
Implementing a Tree with an Array
How these are implemented depends on how the heap is implemented. We can implement trees using a linked structure as we did for binary search trees.
However, we can also implement a tree with an array. Doing this with a heap, we will store the root in array location 0, then the two children of the root in the next two locations. The rule that the heap must be balanced and left-aligned implies that there is only one array location where each item can be stored.

With a linked tree, we can find the left and right children by following the node pointers in each node. In an array we need to calculate the location of each child. Notice that the levels in the tree are stored consecutively with each level having twice the size:
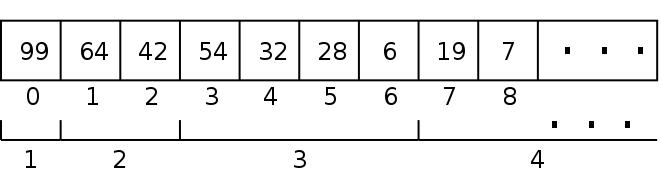
To find the left child of a node, we can use the following formula:
// find the left child of a node
public int left(int node) {
return 2 * node + 1;
}
To find the right child:
// find the right child of a node
public int right(int node) {
return 2 * node + 2;
}
And the parent node:
// find the parent of a node
public int parent(int node) {
return (node - 1) / 2;
}