Binary Trees
Trees
The data structures we have used so far have been linear by nature. Arrays, linked lists, stacks and queues all have a definite start and end. Today we will look at a type of data structure, the tree, for which this is not the case.
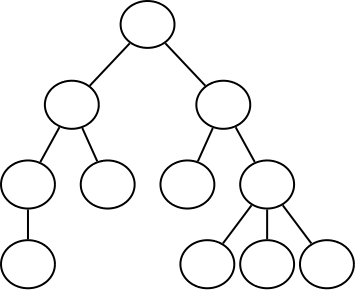
Unlike organic trees, the tree data structure is normally drawn upside down, with the root at the top and leaves at the bottom. There are a few different terms used when discussing trees:
- Node: As with linked lists, a node is simply one element of the tree.
- Root: The root node of a tree is the very topmost node.
- Child: A node is a child of another node if it is below the other and there is a line directly connecting them.
- Parent: A node is a parent of another node if it is above the other and there is a line directly connecting them.
- Leaf: A leaf node is one that has no children.
- Subtree: A subtree is a section of the tree that is a complete tree in its own right, except that its root has a parent.
- Height: The height of the tree is the longest line of nodes from the root to leaf. The height of the above tree is 4.
Trees are naturally recursive data structures. Each subtree can be treated as a full tree allowing us to write recursive functions that deal with trees.
There are many different types of trees which are used for many different applications. Trees are used as the basis for file system and database implementations. They are used for implementing compilers and interpreters. They are also generally useful any time we want to store hierarchical data.
Binary Trees
A binary tree is a type of tree where every node can have at most two children nodes. The two children are typically called the left and right children.
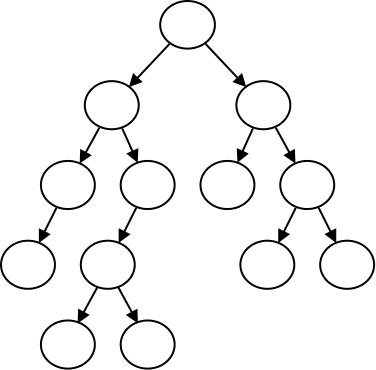
When we are using binary trees inside of a program, we typically create a class for storing the nodes:
// a node in a tree has data, and a left and right subtree
class Node {
int data;
Node left;
Node right;
}
When we did linked lists, we used a node definition similar to the above. The difference for a binary tree is how we will set up our structure. When we create nodes, we will fill in the left and right references such that they refer to children nodes of the tree.
Note that a node can have either or both children references set to null. If both are set to null, than that node is a leaf.
This example demonstrates constructing a binary tree by setting the nodes up directly in code. The tree that this program constructs looks like this:
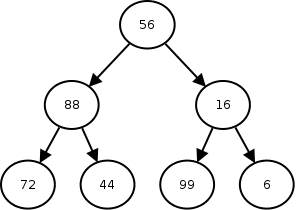
Traversals
With the data structures we have seen so far, looping through each item has been fairly easy. With an array, linked list, or any other kind of linear data structure, there are really only two ways to do, either forwards or backwards.
A tree, however, presents more of a challenge. Where should we start and where should we end? "Looping through" a tree is called traversing it. As we traverse a tree, we "visit" each of the nodes in the tree once.
There are actually three steps that we need to perform to traverse a tree:
- Visit the root node.
- Visit the entire left subtree.
- Visit the entire right subtree.
Like nearly all tree algorithms, this is a recursive process. To visit the left and right subtrees, we recurse and then treat each subtree as if it was the whole tree. The base case for the traversal is when the tree we are traversing has no nodes.
There are actually different ways we can traverse the nodes based on when we visit the root node. If we do it first, we will always visit a node before visiting its children. This is called a preorder traversal.
If we instead change the traversal to visit the root node between the left and right subtrees like so:
- Visit the entire left subtree.
- Visit the root node.
- Visit the entire right subtree.
This will visit the nodes in the tree in a different order. It will always visit the nodes to the left of a given node, then the root, then those to the right. This is called an inorder traversal.
Lastly, if we visit the root node last, then we will have a postorder traversal.
Below is the code for doing these traversals in Java:
public static void preorder(Node node) {
if (node != null) {
System.out.print(node.data + " ");
preorder(node.left);
preorder(node.right);
}
}
public static void inorder(Node node) {
if (node != null) {
inorder(node.left);
System.out.print(node.data + " ");
inorder(node.right);
}
}
public static void postorder(Node node) {
if (node != null) {
postorder(node.left);
postorder(node.right);
System.out.print(node.data + " ");
}
}
Notice that the code is exactly the same in each of these except for the time in which we handle the node we are currently on.