Hash Tables
Overview
Efficiently searchable data is important for many applications. We have seen a few data structures capable of searching. The following table shows the efficiency of searching and inserting into arrays and linked lists:
| Data Structure | Searching | Insertion |
| Unsorted Array/Linked List | $O(N)$ | $O(1)$ |
| Sorted Array | $O(\log N)$ | $O(N)$ |
Hash tables are designed to do both insertion and search very efficiently. In fact the goal of hash tables is to make both of these operations take $O(1)$ time, which is the absolute best that can be done.
Hash Tables
The idea behind a hash table is that we make an array of our items. Then we put each item into an array slot where we will know where to get it when we need it.
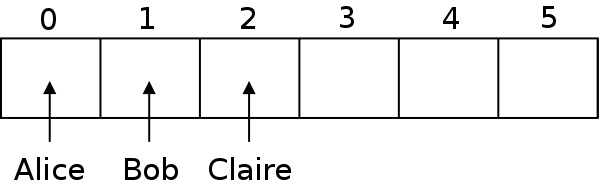
For example, if we have the people "Alice", "Bob", and "Claire", then we can put "Alice" in slot 0, "Bob" in slot 1 and "Claire" in slot 2. Then if we need to look up one of their numbers, we can just look in the same place we stored them.
A hash table has keys and values. The keys are whatever we will use to search. In a phonebook program, the keys will be names.
The values are the actual data we want to store inside of the hash table. In a phonebook program, this would be the phone numbers and addresses.
However, the problem is how can we decide what slot to put our data in?
Hash Functions
The way that we can decide where to put each entry is by using a hash function. A hash function takes our keys that we want to store, and picks a number for it. That number will be used as an index into the array.
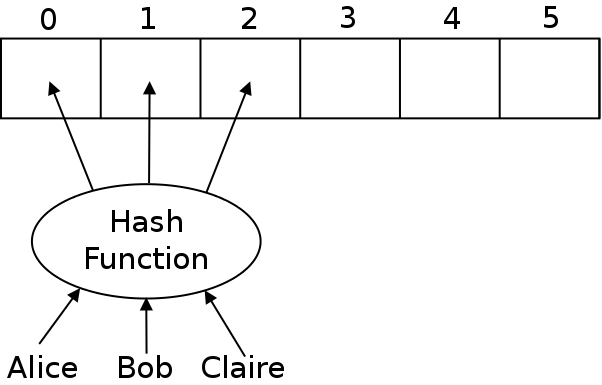
The hash function will map the keys to integers. It must take any key and return the integer to store it at.
The hash function must always return the same number for the same object. That way, when we store the object, we will put it into a given location. Then, when we are searching for it, all we will need to do is run the hash function which will tell us which slot to look in.
If the keys are integers, then the problem is fairly easy. We can just use the keys directly as indices into the table.
However, one issue we have to contend with is making sure that the indices we use are never out of range of the table. For example, if we are using social security numbers as our keys, then the keys will be 9-digit numbers. To use a 9-digit index, the table would need to be one billion entries big.
To avoid this, we can do two things. First we take the absolute value of the number. That will force it to be positive (which is not a problem for social security numbers, but could be for other integers). Next we modulus by the size of the table. That will ensure the number is between 0 and the table size minus one:
public static int hash(int key) {
return Math.abs(key) % TABLE_SIZE;
}
But what about using strings as a key? There are many strategies we can use. A simple one is to add up the ASCII values of each character in the string. Then we can take that total and then again modulus by the size of the table:
Code to do this in Java is shown below:
private static int hash(String name) {
int value = 0;
// add up all the ASCII values
for (int i = 0; i < name.length(); i++) {
value = value + name.charAt(i);
}
// mod by size to prevent overflow
return value % TABLE_SIZE;
}
Simple Example
We can use these ideas to build a simple Hash Table example. This example will create a hash table where the keys are names (a String) and the values are phone numbers (another String). We start by making a PhoneBook class, which stores an array of 117 Strings:
class PhoneBook {
private static int TABLE_SIZE = 117;
private String[] table;
public PhoneBook() {
table = new String[TABLE_SIZE];
}
Next, we have an insert method which uses the hash function for Strings given above to insert a phone number into the table, using the name as the key:
// insert a name
public void insert(String name, String number) {
int index = hash(name);
table[index] = number;
}
We also have a method to lookup a phone number given a name:
// lookup a name
public String lookup(String name) {
// get the index they should be at
int index = hash(name);
// return the data
return table[index];
}
The full code for this example is given in Hashing1.java.
Analysis
Looking at the insert and search methods above, you will notice that they have no loops in them. They both call the hash function, which does loop through the characters of the String it is given.
However, usually the key of the hash table will be of a fixed or relatively small size. For instance, nearly all names are less than, say, 100 characters. Likewise you could use a nine-digit social security number, or other unique identifier as a key while keeping it relatively small. So with a hash table, the size of the table is our $N$, not the size of the keys. Given that, the hash function does not scale up with the input size, and we can say both the insert and lookup methods are $O(1)$.