Nearly all computers these days are parallel machines. Even phones and tablets are multi-core computers, and include multi-core GPUs as well. Only the smallest of micro-controllers are single-core machines these days.
Today, we will look at some issues involved with parallel computer hardware.
Recall that Moore's law says that the number of transistors in a fixed sized integrated circuit doubles every two years. Below is a graph which demonstrates Moore's law:
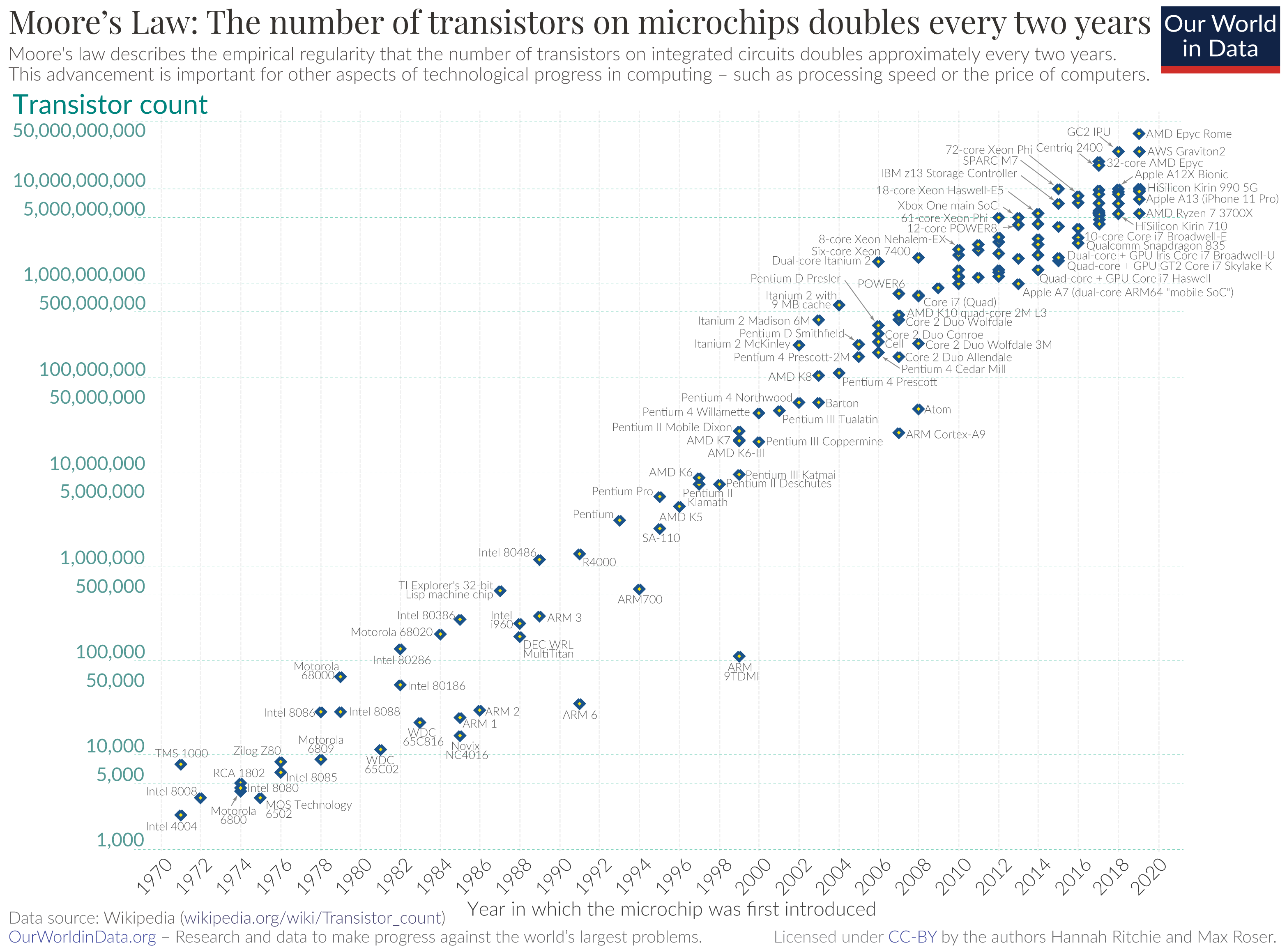
Moore's law has continued up to the present day, but has slowed down. In 2022 Nvidia CEO Jensen Huang stated that Moore's law was dead, while others in the industry disagree. There is no consensus on when it will end, but likely soon.
For most of the duration of Moore's law, hardware designers have packed transistors smaller so as to increase the processor clock speed.
Below is a graph of clock speeds of Intel processors:
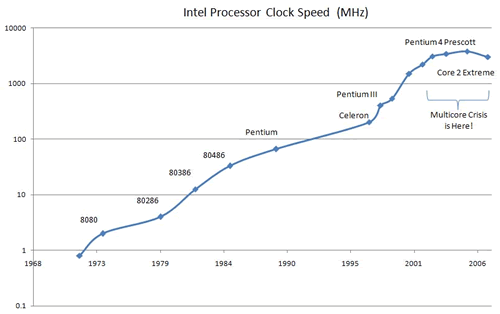
Why did the clock speeds level off in 2006? Why have they still not increased past this point?
Because processors can't continue to increase the clock speed any longer, we use the increased number of transistors Moore's law gives us primarily to do one of two things:
Instruction Parallelism
Executing multiple instructions from one thread at the same time, as in with pipelining, or super scalar execution (fetching multiple instructions at once). This parallelism is handled automatically in hardware, and the programmer does not need to be aware of it. This does not take advantage of more than one core.
Thread Parallelism
Executing multiple threads from one process at a time. Here, the programmer does have to specify the parallelism explicitly. Thread parallelism can be done on a single core, but can be done on multiple cores as well.
Process Parallelism
In process parallelism, multiple separate processes are executing and communicating through some channel provided from the operating system. From the hardware's point of view, this is no different than separate programs executing independently.
In multi-threading, the processor alternates between multiple threads, which may or may not be a part of the same process. There are two major approaches to switching between multiple threads:
Fine-Grained
Here, the processor can switch between threads after every instruction. It can use a round-robin strategy, and will skip threads that have any stalls (e.g. from a cache miss or branch mis-prediction.
For this to work, the processor must have some redundant hardware, such as multiple copies of the register file, program counter, and so on. Instructions identify which thread they are from so that the processor uses the correct values for each thread.
Coarse-Grained
Here, the processor can not switch between threads as easily. When it does decide to, it must do a context switch. This entails saving the contents of the program counter, the register file, and any other status registers. Because of this, context switches are somewhat expensive, and done much less frequently.
All processors must be able to do context switching, because the number of threads is unbounded, but also supporting fine-grained multi-threading offers increased performance.
Different computer systems use different strategies for splitting caches up amongst multiple cores. The i7, as shown below, gives each core its own L1 and L2 cache, but the cores all share one L3 cache:
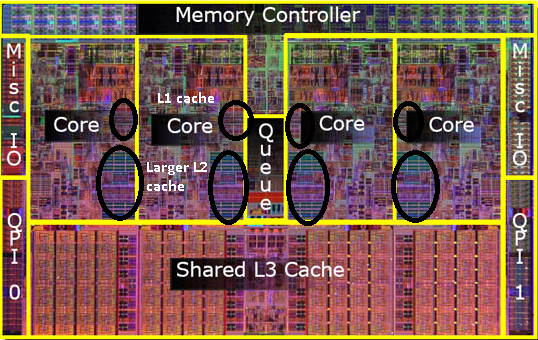
There is another complication of caching that comes into play when we have multiple cores sharing one cache. That is the question of what should really happen when values in the cache are written.
Recall that cached values also exist in higher level caches, and also in main memory. When the processor modifies a value, what should be done with the corresponding entires in main memory (or higher cache levels)?
In a multi-core setup, caching can cause additional issues. What happens if two processors both have a copy of the same value in private caches:
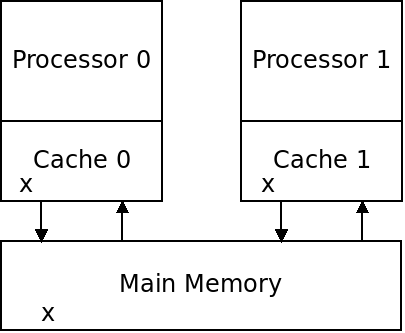
What if both processors write to their copy of x?
Which one should be written back to main memory?
A cache coherence policy attempts to manage these conflicts.
Approaches to cache coherence include:
Invalidation
If a processor writes a value, other copies of it in other caches are marked as being invalid. Future reads of them must go to a higher-level structure.
Update
When a processor writes a value, other copies of it are updated from the old value.
What are the trade-offs between these approaches?
Both of these incur a performance penalty. Even without synchronization, sharing data between threads can result in performance degradation.
Cache coherence has a huge impact on performance and is something programmers must be aware of to write efficient parallel code. Below is part of a program that estimates Pi using multiple threads:
#define THREADS 4
#define TOSSES 50000000
/* global array of random seeds */
int seeds[THREADS];
/* the function called for each thread */
void* estimate_pi(void* idp) {
int number_in_circle = 0, toss;
/* set the seed to our thread id
* this is a pointer to the global array */
unsigned int* seed = &seeds[*(int*)idp];
/* loop through each toss */
for (toss = 0; toss < TOSSES; toss++) {
double x = ((double) rand_r(seed) / (double) RAND_MAX) * 2.0 - 1.0;
double y = ((double) rand_r(seed) / (double) RAND_MAX) * 2.0 - 1.0;
double dist_squared = x*x + y*y;
if (dist_squared <= 1) {
number_in_circle++;
}
}
/* calculater this thread's pi estimate */
double* pi_estimate = malloc(sizeof(double));
*pi_estimate = (4 * number_in_circle) / (double) TOSSES;
pthread_exit(pi_estimate);
}
The program (which uses pthreads), uses random numbers in order to calculate Pi. For the random seeds, which are read every loop iteration, it uses a global array, with one slot for each thread.
The problem is that this small array will fit into one cache line. Therefore we will have coherence problems. The hardware will need to synchronize the values of that cache line across all threads hurting performance.
How long does the program take to execute?
In order to greatly speed up the program, we need to have each thread store its seed in its own cache line. This can be done by replacing the pointer with a local variable in the function:
/* set the seed to our thread id
* this is a LOCAL variable */
unsigned int seed = seeds[*(int*)idp];
Now there is no cache coherence issue. Each thread's seed variable is in a separate cache line, so they do not need to be synchronized. How much faster does the program run now?
Graphics processing units (GPUs) are another type of processor that most computer systems contain. GPUs are primarily used to render graphics onto the screen, but can also now run arbitrary programs.
GPUs are quite different from CPUs:
| CPU | GPU | |
|---|---|---|
| Goal | Latency - finish each individual task quickly. | Throughput - finish a large number of tasks quickly. |
| Typical Cores | 2 to 8 | Thousands |
| Typical Speed | Around 2-4 GHz | Up to 1 GHz |
| Core Independence | Each core runs independently. | Many cores run the same programs. |
GPU cores do not run thousands of independent programs. Instead, they are grouped, and each group runs the same program, but on different data. This works well for graphics when the same transformations are applied to every pixel on the screen.
GPUs are also good for other tasks where the same computations have to be applied across a large amount of data.
Copyright © 2024 Ian Finlayson | Licensed under a Creative Commons BY-NC-SA 4.0 License.